Performances are plateauing, let's make the leaderboard steep again
Evaluating and comparing LLMs is hard. Our RLHF team realized this a year ago when they wanted to reproduce and compare results from several published models. It was a nearly impossible task: scores in papers or marketing releases were given without any reproducible code, sometimes doubtful, but in most cases, just using optimized prompts or evaluation setup to give the best chances to the models. They therefore decided to create a place where reference models would be evaluated in the exact same setup (same questions, asked in the same order, etc.) to gather completely reproducible and comparable results; and that’s how the Open LLM Leaderboard was born!
Following a series of highly visible model releases, it became a widely used resource in the ML community and beyond, visited by more than 2 million unique people over the last 10 months.
Around 300,000 community members use and collaborate on it monthly through submissions and discussions, usually to:
However, with success, both in the leaderboard and the increasing performances of the models came challenges. After one intense year and a lot of community feedback, we thought it was time for an upgrade! Therefore, we’re introducing the Open LLM Leaderboard v2!
Here is why we think a new leaderboard is needed 👇
Over the past year, the benchmarks we were using got overused/saturated:
We thus chose to completely change the evaluations we are running for the Open LLM Leaderboard v2!
We started looking for new benchmarks with uncontaminated, high-quality datasets, using reliable metrics and measuring model capabilities of interest.
We decided to cover the following general tasks: knowledge testing (📚), reasoning on short and long contexts (💭), complex mathematical abilities, and tasks well correlated with human preference (🤝), like instruction following.
We cover these tasks with six benchmarks. Let us present them briefly:
📚 MMLU-Pro (Massive Multitask Language Understanding - Pro version, paper). MMLU-Pro is a refined version of the MMLU dataset. MMLU has been the reference multichoice knowledge dataset. However, recent research showed that it is both noisy (some questions are unanswerable) and now too easy (through the evolution of model capabilities and increased contamination). MMLU-Pro presents the models with ten choices instead of 4, requires reasoning on more questions, and has been expertly reviewed to reduce the amount of noise. It is of higher quality than the original and harder.
📚 GPQA (Google-Proof Q&A Benchmark, paper). GPQA is an extremely hard knowledge dataset, where questions were designed by domain experts in their field (PhD-level in biology, physics, chemistry, etc.) to be hard to answer by laypersons but (relatively) easy for experts. Questions have gone through several rounds of validation to ensure both difficulty and factuality. The dataset is also only accessible through gating mechanisms, which should reduce contamination risks. (This is also why we don’t provide a plain text example from this dataset, as requested by the authors in the paper).
💭MuSR (Multistep Soft Reasoning, paper). MuSR is a very fun new dataset made of algorithmically generated complex problems of around 1K words in length. The problems are either murder mysteries, object placement questions, or team allocation optimizations. To solve these, the models must combine reasoning and very long-range context parsing. Few models score better than random performance.
🧮 MATH (Mathematics Aptitude Test of Heuristics, Level 5 subset, paper). MATH is a compilation of high-school-level competition problems gathered from several sources, formatted consistently using Latex for equations and Asymptote for figures. Generations must fit a very specific output format. We keep only the hardest questions.
🤝 IFEval (Instruction Following Evaluation, paper). IFEval is a fairly interesting dataset that tests the capability of models to clearly follow explicit instructions, such as “include keyword x” or “use format y”. The models are tested on their ability to strictly follow formatting instructions rather than the actual contents generated, allowing strict and rigorous metrics to be used.
🧮 🤝 BBH (Big Bench Hard, paper). BBH is a subset of 23 challenging tasks from the BigBench dataset, which 1) use objective metrics, 2) are hard, measured as language models not originally outperforming human baselines, and 3) contain enough samples to be statistically significant. They contain multistep arithmetic and algorithmic reasoning (understanding boolean expressions, SVG for geometric shapes, etc), language understanding (sarcasm detection, name disambiguation, etc), and some world knowledge. Performance on BBH has been, on average, well correlated with human preference. We expect this dataset to provide exciting insights into specific capabilities which could interest people.
In summary, our criteria were:
Selecting new benchmarks is not the whole story. We also made several other interesting improvements to the leaderboard, which we’ll now briefly cover.
We decided to change the final grade for the model. Instead of summing each benchmark output score, we normalized these scores between the random baseline (0 points) and the maximal possible score (100 points). We then average all normalized scores to get the final average score and compute final rankings. For example, in a benchmark containing two choices for each question, a random baseline will get 50 points (out of 100 points). If you use a random number generator, you will thus likely get around 50 on this evaluation. This means that scores are always between 50 (the lowest score you reasonably get if the benchmark is not adversarial) and 100. We, therefore, change the range so that a 50 on the raw score is a 0 on the normalized score. This does not change anything for generative evaluations like IFEval or MATH.
This change is more significant than it may seem, as it can be seen as changing the weight assigned to each benchmark in the final average score.
In the figure above, we plot the mean scores for our evaluations, with normalized scores on the left and raw scores on the right. If you look at the right side, you would conclude that the hardest benchmarks are MATH Level 5 and MMLU-Pro (lowest raw averages). However, our two hardest evaluations are actually MATH Level 5 and GPQA, which is considerably harder (PhD level questions!) - most models of today get close to random performance on it, and there is thus a huge difference between unnormalized score and normalized score where the random number baseline is assigned zero points!
This change thus also affects model ranking in general. Say we have two very hard evaluations, one generative and one multichoice, with two option samples. Model A gets 0 on the generative evaluation and 52 on the multichoice, and model B gets 10 on the generative and 40 on the multichoice. Looking at the raw averages, you could conclude that model A is better, with an average score of 26, while model B’s average is 25. However, for the multichoice benchmark, they are, in fact, both similarly bad (!): 52 is almost a random score on the multichoice evaluation, and 40 is an unlucky random score. This becomes obvious when taking the normalized scores, where A gets 0, and B gets around 1. However, on the generative evaluation, model B is 10 points better! If we take the normalized averages, we would get 5 for model B and almost 0 for model A, hence a very different ranking.
A year ago, we chose to use the Harness (lm-eval) from EleutherAI to power our evaluations. It provides a standard and stable implementation for several tasks. To ensure fairness and reproducibility, we pinned the version we were using. This allowed us to compare all models in an apples-to-apples setup, as all evaluations were run in exactly the same way, on the same hardware, using the same evaluation suite commit and parameters.
However, lm-eval evolved, and the implementation of some tasks or metrics changed, which led to discrepancies between 1) the evaluation results people would get on more recent versions of the harness and 2) our results using our pinned version.
For the new version of the Open LLM Leaderboard, we have therefore worked together with the amazing EleutherAI team (notably Hailey Schoelkopf, so many, huge kudos!) to update the harness.
On the features side, we added the harness support for delta weights (LoRA finetuning/adaptation of models), a logging system compatible with the leaderboard, and the highly requested use of chat templates for evaluation.
On the task side, we took a couple of weeks to manually check all implementations and generations thoroughly and fix the problems we observed with inconsistent few shot samples, too restrictive end-of-sentence tokens, etc. We created specific configuration files for the leaderboard task implementations, and are now working on adding a test suite to make sure that evaluation results stay unchanging through time for the leaderboard tasks.
You can explore the visualizer we used here!
This should allow us to keep our version up to date with new features added in the future!
Enough was said on the leaderboard backend and metrics. Now, let’s turn to the models and model selection/submission.
Throughout the year, we’ve evaluated more than 7500 models and observed that many of them were not used as much by the community.
The most used ones are usually new base pretrained models, often built using a lot of compute and which the community can later fine-tune for their use cases (such as Meta’s Llama3 or Alibaba’s Qwen2). Some high-quality chat or instruction models find a large user community, such as Cohere’s Command + R, and become strong starting points for community experiments. ♥️
However, the story can be different for other models, even when ranking on top of the leaderboard. Several models are experimental, fascinating and impressive concatenations of more than 20 succesive model creation steps via fine-tuning or merging.
However, these models present some challenges:
To highlight high-quality models in the leaderboard and prioritize the most useful models for evaluation, we’ve therefore decided to introduce a category called “maintainer’s choice” ⭐.
In this list, you’ll find LLMs from a variety of sources, handpicked by the community and the Hugging Face team. We include big companies like Meta or Google, startups like Cohere or Mistral, collectives, like EleutherAI or NousResearch, and users that have shipped great models, among many others.
The list will evolve based on community suggestions and our own observations, and will aim to include as much as possible SOTA LLMs as they come out and keep evaluating these models in priority
We hope it will also make it easier for non-ML users to orient themselves among the many, many models we’ll rank on the leaderboard.
For the previous version of the Open LLM Leaderboard, evaluations were usually run in a queue (“first submitted, first evaluated”) manner. With users sometimes submitting many LLM variants at once and the Open LLM Leaderboard running on the limited compute of the spare cycles on the Hugging Face science cluster, we’ve decided to introduce a voting system for submitted models. The community will be able to vote for models, and we will prioritize running models with the most votes first, surfacing the most awaited models at the top of the priority queue. If a model gets an extremely high number of votes when the cluster is full, we could even consider running it manually instead of other internal jobs at Hugging Face.
To avoid spamming the voting system, users must be connected to their Hugging Face account to vote, and we will save the votes. This system will help us prioritize models that the community is enthusiastic about.
Finally, we’ve been hard at work on improving and simplifying the leaderboard interface itself.
If you’re one of our regular users, you may have noticed that our front end has become much faster in the last month.
This is thanks to the work of the Gradio team, notably Freddy Boulton, who developed a Leaderboard gradio component! It notably loads data on the client side, which makes any column selection or search virtually instantaneous! You can reuse it yourself in your own leaderboard!
We’ve also decided to move the FAQ and About tabs to their own dedicated documentation page!
We’ve started with adding and evaluating the models in the “maintainer’s highlights” section (cf. above) and are looking forward to the community submitting their new models to this new version of the leaderboard!!
Taking a look at the top 10 models on the previous version of the Open LLM Leaderboard and comparing them with this updated version, some models appear to have a relatively stable ranking (in bold below): Qwen-2-72B instruct, Meta’s Llama3-70B instruct, 01-ai’s Yi-1.5-34B chat, Cohere’s Command R + model, and lastly Smaug-72B, from AbacusAI.
We’ve been particularly impressed by Qwen2-72B-Instruct, one step above other models, scoring 43.02 on average (notably thanks to its performance in math, long-range reasoning, and knowledge).
The current second-best model, Llama-3-70B-Instruct (36.67 average), interestingly loses 15 points to its pretrained version counterpart on GPQA (4.92 vs 19.67)! This begs the question of whether the particularly extensive instruction fine-tuning done by the Meta team on this model affected some expert/graduate-level knowledge.
Of course, this ranking is only the beginning of the leaderboard, and we expect it to change soon, as more models get evaluated. You can check the queue status to see which models are currently running!
| Rank | New Leaderboard Ranking |
|---|---|
| ⭐ | Qwen/Qwen2-72B-Instruct |
| 2 | meta-llama/Meta-Llama-3-70B-Instruct |
| 3 | microsoft/Phi-3-medium-4k-instruct |
| 4 | 01-ai/Yi-1.5-34B-Chat |
| 5 | CohereForAI/c4ai-command-r-plus |
| 6 | abacusai/Smaug-72B-v0.1 |
| 7 | Qwen/Qwen1.5-110B |
| 8 | Qwen/Qwen1.5-110B-Chat |
| 9 | microsoft/Phi-3-small-128k-instruct |
| 10 | 01-ai/Yi-1.5-9B-Chat |
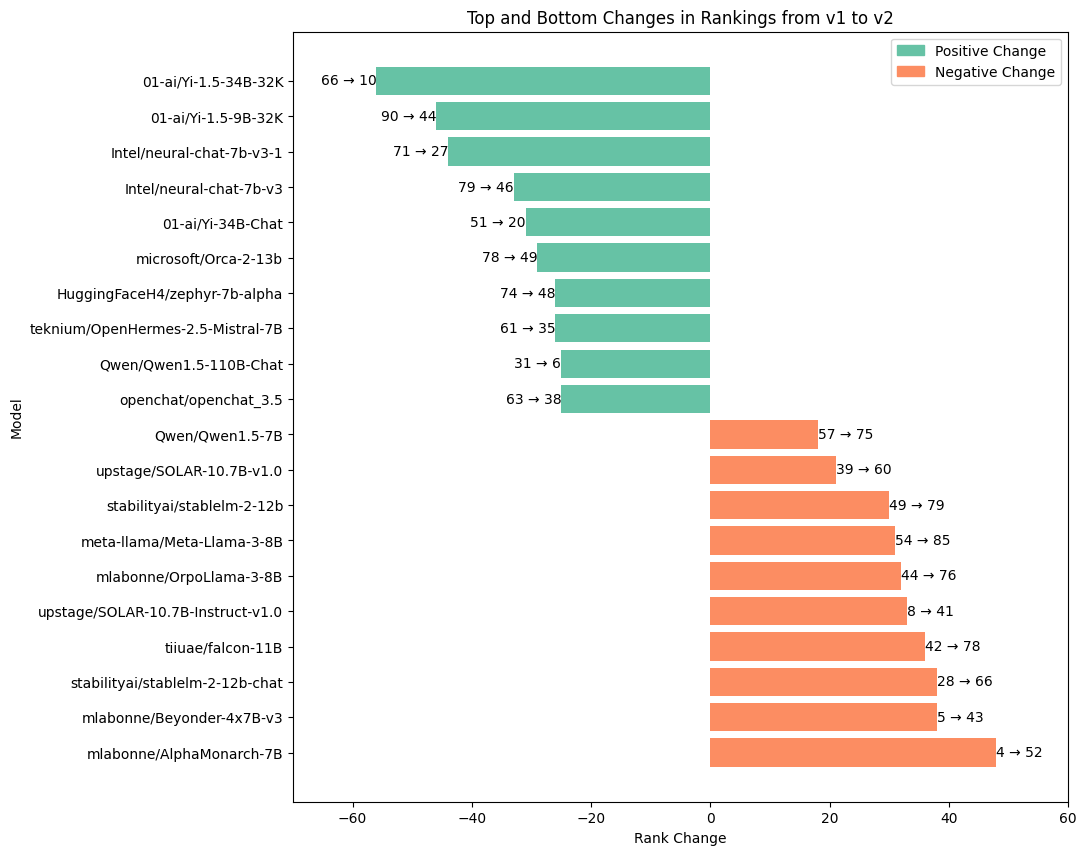
Here is a detail of the changes in rankings:
Let’s finish with some food for thoughts and advice from the maintainer’s team.
Depending on your practical use case, you should focus on various aspects of the leaderboard. The overall ranking will tell you which model is better on average, but you might be more interested in specific capabilities.
In particular, we observed that our different evaluation results are not always correlated with one another as illustrated on this correlation matrix:
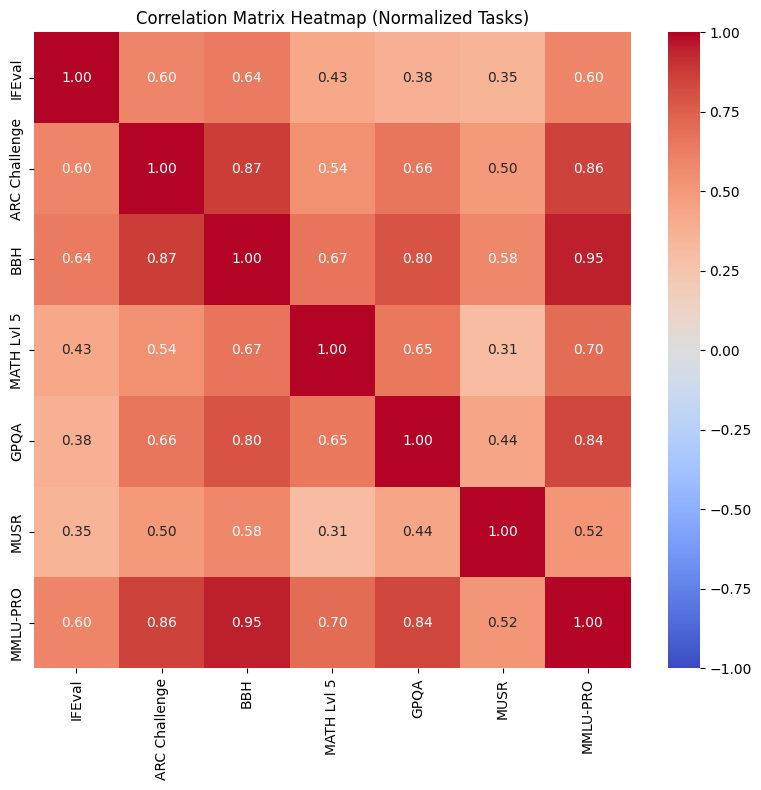
As you can see, MMLU-Pro and BBH are rather well correlated. As other teams have noted, these benchmarks are also quite correlated with human preference (for instance, they tend to align with human judgment in LMSys’s chatbot arena).
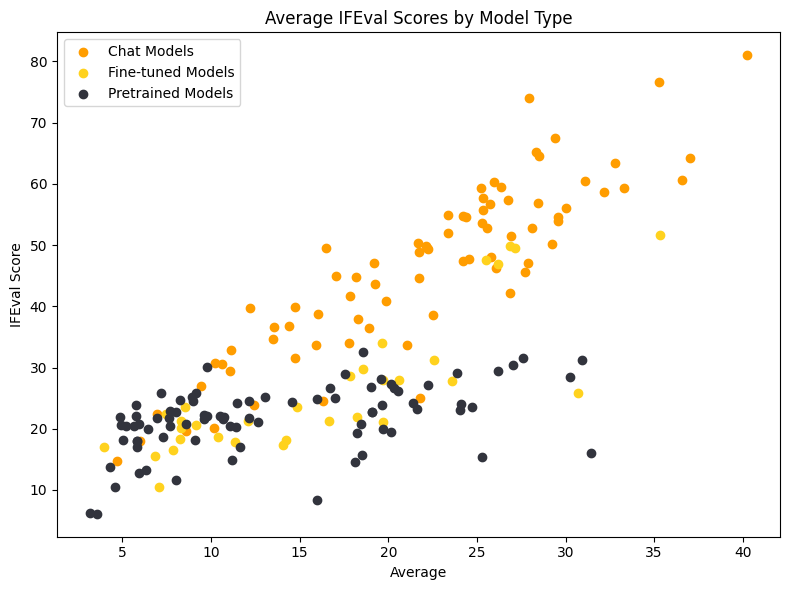
Another of our benchmarks, IFEval, targets chat capabilities. It investigates whether models can follow precise instructions. However, the format used in this benchmark tends to favor chat and instruction-tuned models, with pretrained models having a harder time reaching high performances.
If you are especially interested in model knowledge rather than alignment or chat capabilities, the most relevant evaluations for you will likely be MMLU-Pro and GPQA.
Let’s see how performances on these updated benchmarks compare to our evaluation on the previous version of the leaderboard.
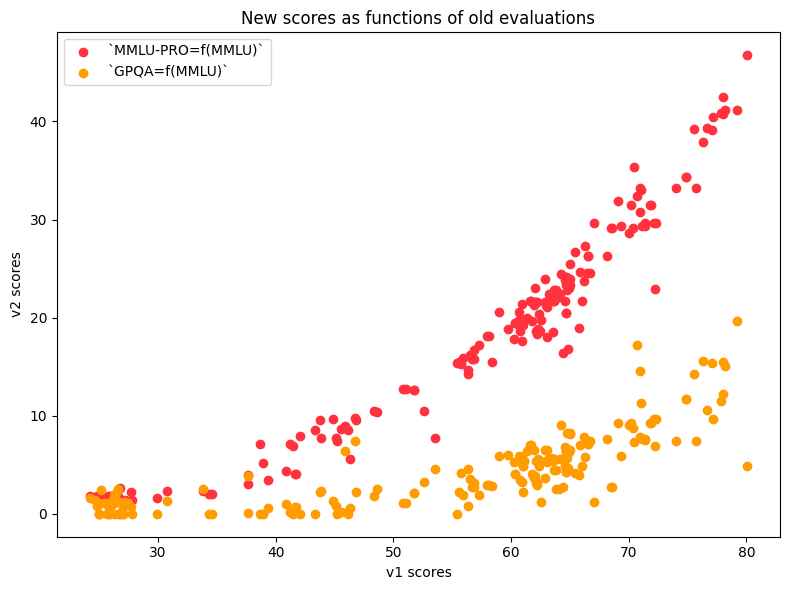
As we can see, both MMLU-PRO scores (in orange) and GPQA scores (in yellow) are reasonably correlated with MMLU scores from the Open LLM Leaderboard v1. However, we note that the scores are overall much lower since GPQA is much harder. There is thus quite some room for the model to improve – which is great news :)
MATH-Lvl5 is obviously interesting for people focusing on math capabilities. The results on this benchmark are generally correlated with performance on GSM8K, except for some outliers, as we can see in the following figure.
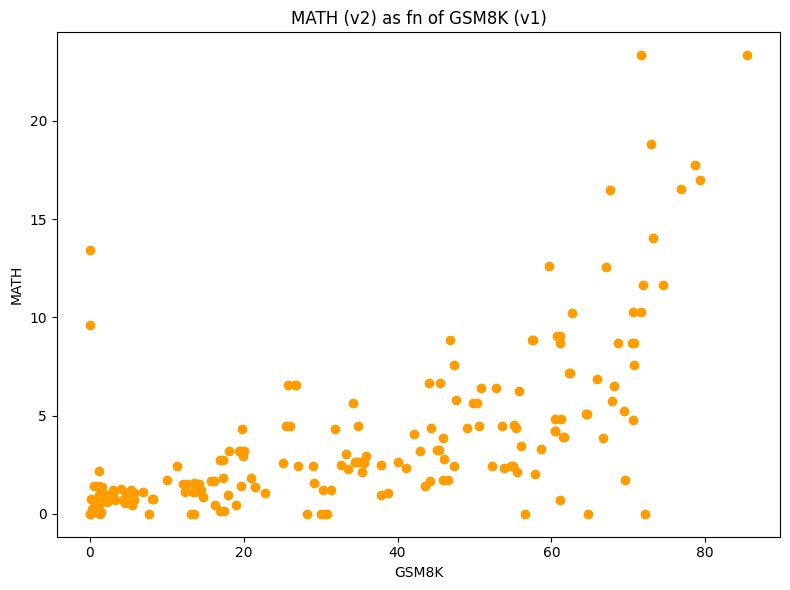
The green dots highlight models which previously scored 0 on GSM8K due to evaluation limitations mentioned above but now have very decent scores on the new benchmark MATH-Level5. These models (mostly from 01-ai) were quite strongly penalized by the previous format. The red dots show models which scored high on GSM8K but are now almost at 0 on MATH-Lvl5.
From our current dive in the outputs and behaviors of models, chat versions of base models sometimes have a considerably lower score than the original models on MATH! This observation seems to imply that some chat finetuning procedures can impair math capabilities (from our observations, by making models exceedingly verbose).
MuSR, our last evaluation, is particularly interesting for long-context models. We’ve observed that the best performers are models with 10K and plus of context size, and it seems discriminative enough to target long context reasoning specifically.
Let’s conclude with a look at the future of Open LLM leaderboard!
Much like the first version of the Open LLM Leaderboard pushed a community approach to model development during the past year, we hope that the new version 2 will be a milestone of open and reproducible model evaluations.
Because backward compatibility and open knowledge are important, you’ll still be able to find all the previous results archived in the Open LLM Leaderboard Archive!
Taking a step back to look at the evolution of all the 7400 evaluated models on the Open LLM Leaderboard through time, we can note some much wider trends in the field! For instance, we see a strong trend going from larger (red dots) models to smaller (yellow dots) models while at the same time improving performance.
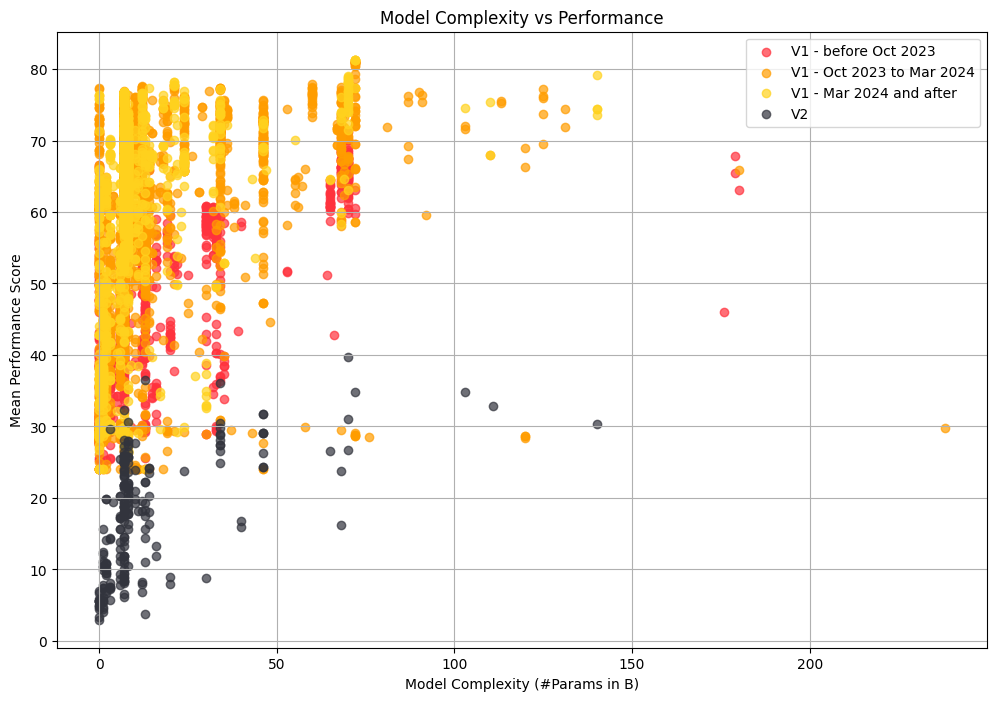
This is great news for the field as smaller models are much easier to be embedded and much more energy/memory/compute efficient, and we hope to observe a similar pattern of progress in the new version of the leaderboard. Given our harder benchmarks, our starting point is much lower (black dots), so let’s see where the field takes us in a few months from now :)
If you’ve read to this point, thanks a lot. We hope you’ll enjoy this new version of the Open LLM Leaderboard. May the open-source winds push our LLMs boats to sail far away on the sea of deep learning ⛵